Sharing links through physical media is not trivial, because the recipient has to type them out manually. I recently encountered this problem at work, where we had to share a SharePoint document link through a PowerPoint. A custom link was created with a link shortener, making it easier to type. Later, the SharePoint link broke during an update, but the original creator had left the company. I wanted a service that would make it easy to edit a link later. Combined with my interest in diving into the technical aspects of link shorteners, I decided to build AnchorURL. The idea was to optimize it for speed and robustness, while keeping it as cheap to run as possible. This post explores the different techniques I used.
Redirection
There are several HTTP status codes that indicate redirection: 301, 302, 303, 307, 308. 302 and 307 both indicate temporary redirection, which is what’s needed, since the target location can change later. The technical difference between the two is whether they preserve the HTTP method. Since the project only supports the GET method, the choice is arbitrary. I chose 307 because it is called Temporary Redirect, which felt most appropriate.
The idea is that the client sends an HTTP PUT /{link} request with the target URL in the body. Any subsequent HTTP GET /{link} request will then redirect to that URL. The response to the PUT includes an edit-secret, which the client can later use to update the link.
Optimizations
The central structure of the application is a HashMap containing all the links. This keeps reads simple and fast. To allow updates, a RwLock is used to support multiple reads and a single write. This enables asynchronous access in the backend.
The common way to store data is in a database. However, running a database is expensive and overkill for a simple project. Instead, I used the file system for storage. Whenever a link is created, a corresponding file is created. This keeps all data in memory while still allowing rehydration when the application shuts down or crashes.
Having worked mostly with high-level abstractions, I assumed storing data in a file was crash-safe. However, when looking into the implementation, I discovered that the Linux file system does not actually guarantee that a file write completes. To ensure a file is created, it must be flushed from the OS file buffer. This is done with a call to fsync, which only returns once all data is safely written. This is easily the biggest bottleneck in the system, but it’s a tradeoff for crash-safety. Not calling it makes the application faster but introduces a small risk of data loss. I chose crash-safety for this project.
UI
The frontend was fairly simple, so I wanted to keep everything in a single HTML file. This made it easier to serve to the user and avoided unnecessary complexity. While this is good for maintainability, it was frustrating not to have the convenience of reusable components that most frameworks provide.
In the first version of the frontend, I tried generating code with Claude. This produced a huge file with 1,200 lines of code that still didn’t meet my requirements. The context also became too large, and the chat broke when I tried to start a new one. The result of that first generated version looked like this:
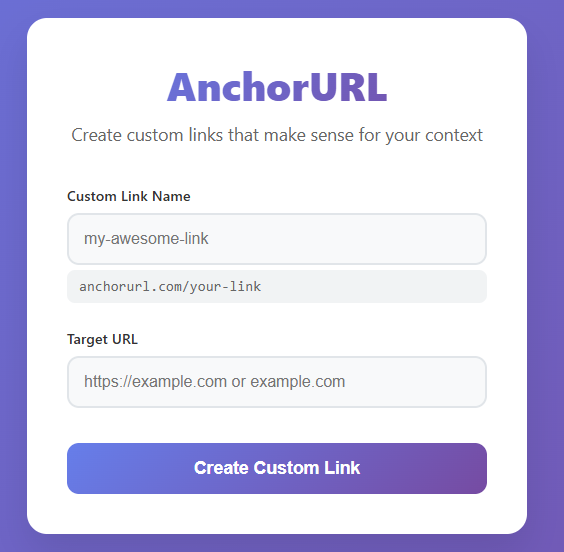
I tried fixing the generated page, but there were too many issues, and I disliked the style and size of the code. I attempted redoing it, but ended up in the same situation: 1,000+ lines of code, many broken features, and a style I wasn’t happy with. It seemed to always generate a few specific themes, and whenever I asked for changes, everything broke. I suspect the system prompt or training data biases it toward certain styles. For example, when I asked for dark mode, it always wanted to generate a GitHub-like dark theme.
So I decided to write it entirely by hand and ended up with everything working in around 500 lines of HTML, CSS, and JavaScript. That version looked like this:
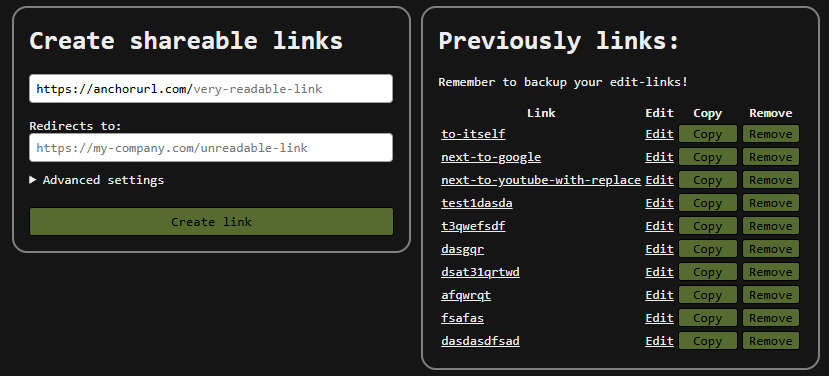
I spent a lot of time thinking about different design decisions:
- The link input field lets you type a link and see what the final URL becomes.
- The placeholders provide context for the project’s purpose.
- The advanced settings include explanations and examples of the query parameter forwarding option.
- When creating, the focus is on the link field; when editing, the focus is on the URL field.
- The advanced section automatically opens and closes on edit depending on the chosen options.
- The copy button gives feedback when clicked.
- If “Create link” is clicked and the same error persists, the input field shakes to indicate the error is still present.
- The remove button was intentionally placed farther from edit, since these are the two primary actions, and I didn’t want users to accidentally press remove.
I ran a Lighthouse report to verify best practices, and it scored 100 in all categories except Accessibility. The issue was button color contrast. I chose not to fix it because I preferred the original color, and the higher-contrast options were harder on the eyes.
Query Parameter Forwarding
To make things more interesting, I introduced query parameter forwarding options. The idea was to let the user choose between a few different behaviors:
- Ignore: always redirect to the given URL.
- Append: append the query parameters to the given URL.
- Replace: replace the query parameters entirely. A default can also be set.
- Combine and ignore: combine them while ignoring overwrites.
- Combine and replace: combine them while replacing overwrites.
For example, a link /test pointing to test.com?query1=123&query2=456 and called as /test?query2=654&query3=789 would result in:
- Ignore:
test.com?query1=123&query2=456 - Append:
test.com?query1=123&query2=456&query2=654&query3=789 - Replace:
test.com?query2=654&query3=789 - Combine and ignore:
test.com?query1=123&query2=456&query3=789 - Combine and replace:
test.com?query1=123&query2=654&query3=789
It took a while to figure out the different options, but I believe this covers most use cases. The most interesting challenge is when two query parameters share the same name. Many frameworks use this pattern to support lists, so it had to be handled carefully. Another challenge was presenting these options in a helpful way in the UI.
Hosting
Hosting is done through DigitalOcean, which offers a shared CPU server for $7 a month. This is the primary cost of keeping the project alive. They also have a slightly cheaper option, but this one seemed the best fit.
The second expense is the domain, which costs $11 per year. It’s registered through NameCheap, which also includes free email forwarding for the domain.
The server runs Ubuntu, with everything set up using standard Systemd services. HTTPS is handled by Nginx with Certbot for certificate management. The backend is then hosted internally on the server. This setup also allows redeployment with no visible downtime.
Deployment is handled through GitHub Actions, which SSHs into the server to compile and run the binary. It’s set up with CI in mind, so once all tests pass successfully, it automatically redeploys.
Health checks are also handled by GitHub Actions, which periodically call the application and send an email if a failure occurs.
Performance
To verify performance, I set up a JMeter test. The application handled around 2.6K requests per second with a 110 ms response time (including 20 ms network latency). This was tested with 300 concurrent connections. Performance would likely be worse if each user had to perform a full HTTPS handshake.
This seemed good enough for a project with zero users running on limited hardware. If the project gains traction, the first performance improvement would probably be upgrading the server.
Another possible optimization relates to locking. Right now, a central lock is used, but with a large enough dataset it would be worth optimizing the locking strategy further. This is closely related to my bachelor project, so it’s something I’ll likely revisit with a custom implementation.
Result
The result is AnchorURL. Go check it out!